0
Lista vacía
No has añadido ningún curso

¡Bienvenidos a un viaje emocionante a través del apasionante universo del Streaming Processing en el contexto del Big Data! En la era digital actual, donde la información fluye a velocidades vertiginosas y el volumen de datos es simplemente abrumador, surge la imperiosa necesidad de procesar y comprender esta marea de información en tiempo real. Y aquí es donde entra en juego el fascinante concepto de Streaming Processing.
Durante esta emocionante exploración del mundo del Streaming Processing, te animamos a que, si deseas profundizar aún más, te recomendamos nuestro curso gratis de arquitectura de Big Data, consideres inscribirte en nuestro curso gratuito. ¡Inscríbete hoy mismo y da un paso adelante en tu camino hacia la maestría en el procesamiento de datos!

Imagina estar al tanto de cada cambio, cada evento y cada tendencia en el momento en que ocurren, como si estuvieras leyendo las noticias en tiempo real, pero aplicado a la ingente cantidad de datos generados por máquinas, aplicaciones y usuarios. Desde detectar fraudes en transacciones financieras en el instante exacto en que ocurren, hasta analizar las reacciones del público en las redes sociales a medida que se desarrollan los eventos, el Streaming Processing nos brinda la capacidad de obtener información valiosa y procesada al vuelo.
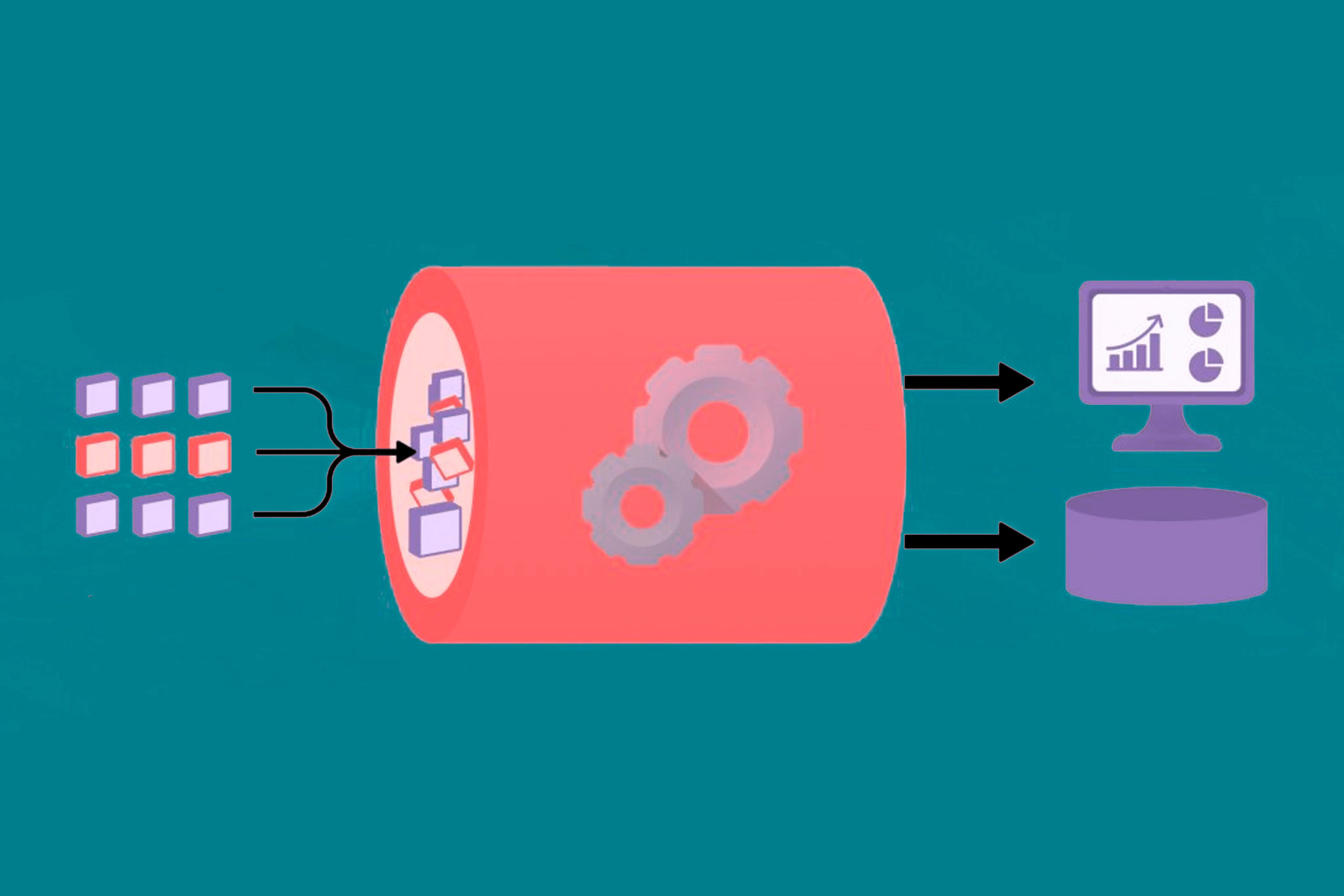
El Streaming Processing, o procesamiento en tiempo real, es una técnica avanzada que nos permite analizar, transformar y actuar sobre datos en constante flujo, a medida que son generados. A diferencia del procesamiento por lotes, donde los datos se acumulan y se procesan en grupos, el Streaming Processing opera en una corriente continua de información, permitiéndonos tomar decisiones instantáneas y adaptarnos a cambios en tiempo real.
¡Es hora de sumergirnos en el torrente de datos y dominar el arte del Streaming Processing!
El Streaming Processing, o procesamiento en tiempo real, es la columna vertebral que sostiene el Big Data en la era digital actual. A medida que el flujo constante de datos se convierte en la norma, comprender los fundamentos de esta técnica se vuelve esencial para aprovechar al máximo la información en tiempo real. En esta sección, exploraremos en detalle los elementos esenciales del Streaming Processing y su importancia en el panorama actual.
En su esencia, el Streaming Processing se refiere a la capacidad de analizar y procesar datos mientras están en movimiento, en lugar de esperar a que se acumulen en lotes. En lugar de trabajar con archivos estáticos, como en el procesamiento por lotes tradicional, el Streaming Processing se centra en flujos continuos de información en constante actualización.
– Tiempo Real: El procesamiento ocurre en tiempo real, permitiendo respuestas y acciones instantáneas ante eventos en curso.
– Escalabilidad: La capacidad de manejar grandes volúmenes de datos sin degradar el rendimiento.
– Latencia Baja: Los resultados se generan rápidamente, lo que es crucial para aplicaciones en tiempo real.
– Procesamiento Continuo: Los datos se procesan a medida que llegan, lo que permite la detección temprana de patrones y tendencias.
Para comprender mejor la diferencia entre el Streaming Processing y el procesamiento por lotes, imaginemos una tienda de helados. En el procesamiento por lotes, el dueño de la tienda toma todos los pedidos de helados durante una hora y luego los prepara juntos. En el Streaming Processing, por otro lado, el dueño prepara y sirve cada pedido de helado a medida que llega, asegurándose de que los clientes obtengan sus helados frescos y rápidamente.
– Respuesta en Tiempo Real: Permite tomar decisiones instantáneas basadas en datos actuales.
– Detección Temprana: Facilita la identificación de problemas o patrones a medida que surgen.
– Eficiencia de Recursos: Evita el procesamiento innecesario de datos y ahorra recursos.
– Latencia: El procesamiento instantáneo puede ser demandante en términos de recursos.
– Complejidad: Requiere un enfoque diferente en diseño y arquitectura en comparación con el procesamiento por lotes.
El Streaming Processing encuentra aplicación en diversas áreas, desde la detección de fraudes financieros hasta el análisis de sentimientos en redes sociales. Algunos casos de uso notables incluyen:
1. Detección de Fraudes en Tiempo Real: Las transacciones financieras se pueden analizar mientras ocurren para identificar patrones sospechosos y detener el fraude de manera inmediata.
2. Análisis de Redes Sociales: Las opiniones y reacciones en las redes sociales se pueden monitorear en tiempo real para evaluar la recepción de un producto o evento.
3. Optimización de Tráfico: Los sistemas de navegación pueden utilizar datos de tráfico en tiempo real para proporcionar rutas más eficientes.
Imagina que eres el gerente de una cadena de supermercados. Utilizando Streaming Processing, puedes rastrear las ventas de cada producto en todas tus tiendas en tiempo real. A medida que se realizan las compras, los datos se transmiten a un sistema de procesamiento que analiza las tendencias de compra. Si una tendencia muestra un aumento repentino en la venta de productos relacionados con la playa, podrías tomar medidas para aumentar el suministro de artículos relacionados antes de que llegue la temporada de verano. Esto te permite satisfacer la demanda de los clientes de manera proactiva y maximizar las ventas.
A medida que nos adentramos en el emocionante mundo de las herramientas y tecnologías en Streaming Processing, comprender estos conceptos fundamentales nos brinda la base para aprovechar al máximo el Big Data en tiempo real.
En el vertiginoso mundo del procesamiento en tiempo real, Apache Spark emerge como una luminaria destacada gracias a su módulo Spark Streaming. Con su capacidad para procesar flujos de datos continuos con la misma facilidad que lo hace con el procesamiento por lotes, Spark Streaming se presenta como una herramienta esencial para aquellos que desean aprovechar al máximo el Big Data en tiempo real. En esta sección, exploraremos las maravillas de Spark Streaming, su arquitectura distintiva y cómo puede revolucionar la forma en que interactuamos con los datos en movimiento.
Para comprender Spark Streaming, primero debemos echar un vistazo a Apache Spark en su conjunto. Spark es un framework de procesamiento de datos en clúster que ha capturado la atención del mundo tecnológico debido a su velocidad, versatilidad y elegancia en el manejo de grandes volúmenes de datos. Y Spark Streaming es su faceta más reluciente cuando se trata de datos en tiempo real.
La magia detrás de Spark Streaming radica en su arquitectura basada en microbatches. En lugar de procesar eventos de manera individual, Spark Streaming agrupa los datos en pequeños lotes, permitiendo un procesamiento eficiente y rápido. Estos microbatches se procesan en intervalos de tiempo específicos, lo que permite un equilibrio entre la latencia y el rendimiento.
1. Adquisición de Datos: Los flujos de datos son adquiridos de diversas fuentes, como Kafka, sistemas de archivos o sockets de red.
2. División en Microbatches: Los datos se agrupan en microbatches, creando fragmentos manejables para el procesamiento.
3. Procesamiento: Cada microbatch se procesa mediante operaciones similares a las de Spark en el modo por lotes.
4. Generación de Resultados: Los resultados se generan al final de cada intervalo y pueden ser almacenados o accedidos en tiempo real.
Una de las ventajas más notables de Spark Streaming es su integración fluida con las otras bibliotecas y módulos de Spark. Esto significa que puedes aplicar las mismas operaciones y transformaciones que usas en el procesamiento por lotes a tus flujos de datos en tiempo real. Desde el filtrado hasta el agrupamiento y el análisis de datos, las posibilidades son prácticamente infinitas.
Imagina que estás supervisando una red de sensores IoT que monitorean la calidad del aire en una ciudad. Utilizando Spark Streaming, puedes procesar los datos recopilados por estos sensores en tiempo real y generar alertas si se detectan niveles peligrosos de contaminantes. Aquí hay un breve resumen de cómo podrías hacerlo:
1. Adquisición de Datos: Los sensores envían datos de calidad del aire a una cola de mensajes Kafka.
2. Configuración de Spark Streaming: Creas un flujo de Spark Streaming que se conecta a la cola Kafka y define la ventana de tiempo para el procesamiento.
3. Procesamiento en Tiempo Real: Aplicas transformaciones y operaciones de Spark en los microbatches de datos para analizar los niveles de contaminantes.
4. Generación de Alertas: Si se detecta un nivel peligroso de contaminantes, puedes generar alertas en tiempo real y tomar medidas inmediatas.
Su arquitectura basada en microbatches y su integración perfecta con otras bibliotecas de Spark lo convierten en un aliado invaluable para enfrentar los desafíos del Big Data en constante movimiento.
En el emocionante campo del Streaming Processing, donde la velocidad y la precisión son esenciales, dos nombres destacan como alternativas de vanguardia: Apache Pulsar y Apache Apex. Estas tecnologías de procesamiento en tiempo real han irrumpido en el panorama, ofreciendo soluciones innovadoras y escalables para el procesamiento de flujos de datos continuos. En esta sección, exploraremos las características únicas de Pulsar y Apache Apex, y cómo pueden impulsar tus capacidades de procesamiento en tiempo real.
Apache Pulsar se presenta como una plataforma de mensajería y streaming diseñada para ofrecer un procesamiento en tiempo real confiable y escalable. Lo que distingue a Pulsar es su arquitectura de múltiples niveles, que brinda una flexibilidad excepcional al manejar flujos de datos.
– Tolerancia a Fallos y Garantía de Entrega: Pulsar garantiza la entrega confiable de mensajes incluso en situaciones de fallos en el sistema.
– Escalabilidad Horizontal: Pulsar permite escalar fácilmente los componentes individuales para adaptarse al crecimiento del flujo de datos.
– Múltiples Niveles de Almacenamiento: La arquitectura de almacenamiento en varios niveles permite mantener los datos por diferentes períodos y costos.
–Soporte para Mensajes y Streams: Pulsar admite tanto el modelo de mensajes como el de transmisión, brindando flexibilidad en el procesamiento.
Apache Apex ofrece una perspectiva única en el mundo del Streaming Processing al enfocarse en el procesamiento en estado nativo. Aprovechando su modelo de programación de flujo de datos, Apex permite el procesamiento continuo y en estado en aplicaciones en tiempo real.
–Procesamiento en Estado: Apex permite el almacenamiento y el análisis continuo de datos a medida que fluyen, habilitando análisis avanzados.
–Escalabilidad Automatizada: La plataforma se encarga de la escalabilidad automática según los requisitos de procesamiento.
– Lenguaje de Programación Unificado: Apex admite múltiples lenguajes de programación, lo que facilita la integración con diversas aplicaciones.
– Biblioteca de Operadores: Apex ofrece una variedad de operadores predefinidos para agilizar el desarrollo de aplicaciones de streaming.
Imaginemos que trabajas en una empresa de análisis de tráfico urbano. Utilizando Apache Pulsar, puedes recibir datos de sensores de tráfico en tiempo real y transmitirlos a un sistema de procesamiento. A medida que los datos fluyen, Pulsar garantiza que se procesen sin pérdida y se almacenen en diferentes niveles para análisis históricos y en tiempo real.
Por otro lado, si tu objetivo es procesar datos de tráfico en estado continuo y realizar análisis en tiempo real, Apache Apex sería tu elección ideal. Puedes desarrollar aplicaciones que calculen la velocidad promedio del tráfico, identifiquen congestiones y generen alertas en caso de eventos anómalos, todo en un flujo de datos en constante actualización.
En resumen, tanto Apache Pulsar como Apache Apex representan alternativas vanguardistas para el procesamiento en tiempo real. Ya sea que busques la flexibilidad de Pulsar o el procesamiento en estado de Apex, estas tecnologías te permiten enfrentar los desafíos del Streaming Processing con soluciones de vanguardia.
Llegamos al meollo del asunto: la implementación práctica de un sistema en tiempo real utilizando herramientas de Streaming Processing. En esta sección, te guiaré a través de los pasos clave para crear un sistema que procese flujos de datos en tiempo real, permitiéndote experimentar directamente la potencia y la emoción del procesamiento en vivo.
Antes de sumergirnos en el código, es fundamental establecer una base sólida para el diseño y la planificación del sistema. Define claramente los objetivos del proyecto, los flujos de datos que se deben procesar y los resultados que esperas obtener. Considera los siguientes aspectos:
1. Objetivos Claros: ¿Qué quieres lograr con tu sistema en tiempo real? Identifica los KPI clave y las metas a alcanzar.
2. Fuentes de Datos: ¿De dónde vendrán los flujos de datos? Pueden ser sensores IoT, redes sociales, registros de eventos, etc.
3. Arquitectura: Decide qué herramientas utilizarás para el procesamiento. ¿Optarás por Spark Streaming, Pulsar, Apex u otra tecnología?
4. Escalabilidad: Anticipa el crecimiento futuro y asegúrate de que tu arquitectura pueda manejar un aumento en el volumen de datos.
Para esta implementación, optaremos por Spark Streaming debido a su amplia adopción y facilidad de uso. Asegúrate de tener instalado Apache Spark y configurado tu entorno de desarrollo. A continuación, sigamos los pasos:
1. Configura una fuente de datos para simular flujos en tiempo real. Puede ser un archivo de registros o una fuente de Kafka.
1. Importa las bibliotecas necesarias de Spark Streaming.
2. Crea un `SparkConf` y un `StreamingContext`.
3. Configura el intervalo de tiempo para los microbatches (por ejemplo, 1 segundo).
1. Crea un flujo de datos utilizando la fuente configurada en el Paso 1.
2. Aplica transformaciones y operaciones de Spark en el flujo de datos (filtrado, mapeo, reducción, etc.).
1. Define cómo deseas presentar los resultados. Puede ser la impresión en la consola o el almacenamiento en un sistema de almacenamiento persistente.
1. Inicia el flujo de Spark Streaming utilizando `ssc.start()`.
2. Monitorea el progreso y los resultados utilizando el panel de control web de Spark.
1. Analiza el rendimiento del sistema y ajusta los parámetros según sea necesario.
2. Asegúrate de que el sistema sea escalable y pueda manejar un aumento en la carga.
La implementación de un sistema en tiempo real es una experiencia emocionante que te permite interactuar directamente con flujos de datos en movimiento. A medida que dominas el arte del Streaming Processing, puedes aplicar estas habilidades a una amplia gama de casos de uso, desde el análisis de redes sociales hasta la monitorización de la infraestructura de IoT. ¡Adelante, pon en práctica tus conocimientos y descubre todo lo que el mundo del procesamiento en tiempo real tiene para ofrecer!
El viaje a través del emocionante mundo del Streaming Processing nos ha llevado a descubrir un universo de posibilidades para aprovechar al máximo el Big Data en tiempo real. Desde los fundamentos hasta la implementación práctica, hemos explorado las herramientas y tecnologías clave que impulsan esta revolución en el procesamiento de datos. En esta sección final, recapitularemos lo aprendido y reflexionaremos sobre el impacto y el futuro del Streaming Processing.
– Respuesta en Tiempo Real: El Streaming Processing nos permite tomar decisiones instantáneas y acciones basadas en datos en movimiento, lo que es fundamental en escenarios dinámicos.
– Detección Temprana: La capacidad de analizar flujos de datos continuos nos permite identificar patrones, anomalías y tendencias a medida que surgen, lo que es esencial para la toma de decisiones efectivas.
– Escalabilidad: Las tecnologías de Streaming Processing, como Spark Streaming, Pulsar y Apex, ofrecen soluciones escalables que pueden manejar grandes volúmenes de datos en tiempo real.
Hemos explorado tres tecnologías clave en Streaming Processing: Spark Streaming, Pulsar y Apex. Cada una de estas herramientas ofrece enfoques únicos para el procesamiento en tiempo real, con características distintivas que se adaptan a diferentes casos de uso y necesidades empresariales. Spark Streaming brilla por su integración con el ecosistema Spark y su arquitectura de microbatches, Pulsar sobresale por su garantía de entrega y escalabilidad horizontal, mientras que Apex se destaca por su enfoque en el procesamiento en estado nativo.
El dominio del Streaming Processing continuará evolucionando a medida que la demanda de análisis en tiempo real siga creciendo. Con el auge del Internet de las Cosas (IoT), el procesamiento de flujos de datos se volverá aún más crucial en una amplia gama de industrias, desde la salud hasta la fabricación y más allá.
También podemos anticipar avances tecnológicos que optimicen aún más la latencia y la eficiencia del procesamiento en tiempo real. Nuevas bibliotecas, herramientas y marcos de trabajo seguramente surgirán para abordar desafíos específicos y expandir las capacidades del Streaming Processing.
Concluimos nuestro viaje con la confianza de que has adquirido un entendimiento sólido de los fundamentos, las herramientas y las técnicas necesarias para dominar el procesamiento en tiempo real. Ya estás equipado para enfrentar los desafíos del Big Data en constante movimiento y aprovechar sus oportunidades. A medida que sigas explorando y aplicando tus conocimientos, recuerda que el arte del Streaming Processing es una llave maestra para desbloquear una nueva dimensión de insights, acciones y descubrimientos en el vasto y emocionante mundo del Big Data.
¡Adelante, maestro del Streaming Processing, el futuro está en tus manos!